Introduction
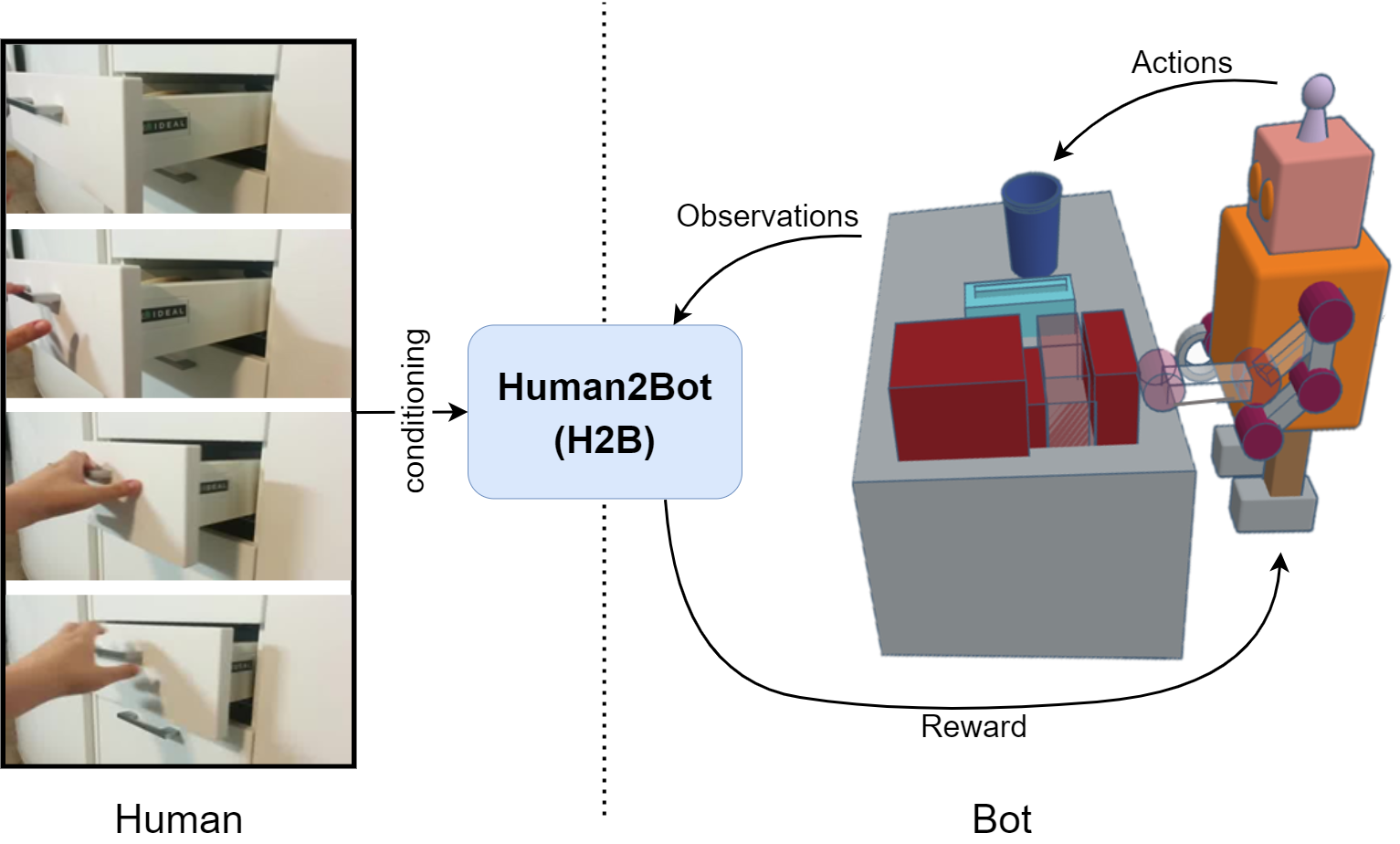
Left: A human demonstration is given (e.g., closing a drawer). Right: The robot learns to deduce the task through its interactions with the environment by executing actions and recording observations. H2B evaluates each sequence of observations based on its similarity to the human demonstration and provides reward on the robot’s performance, guiding it to accomplish the task like the human.
Proposed Method
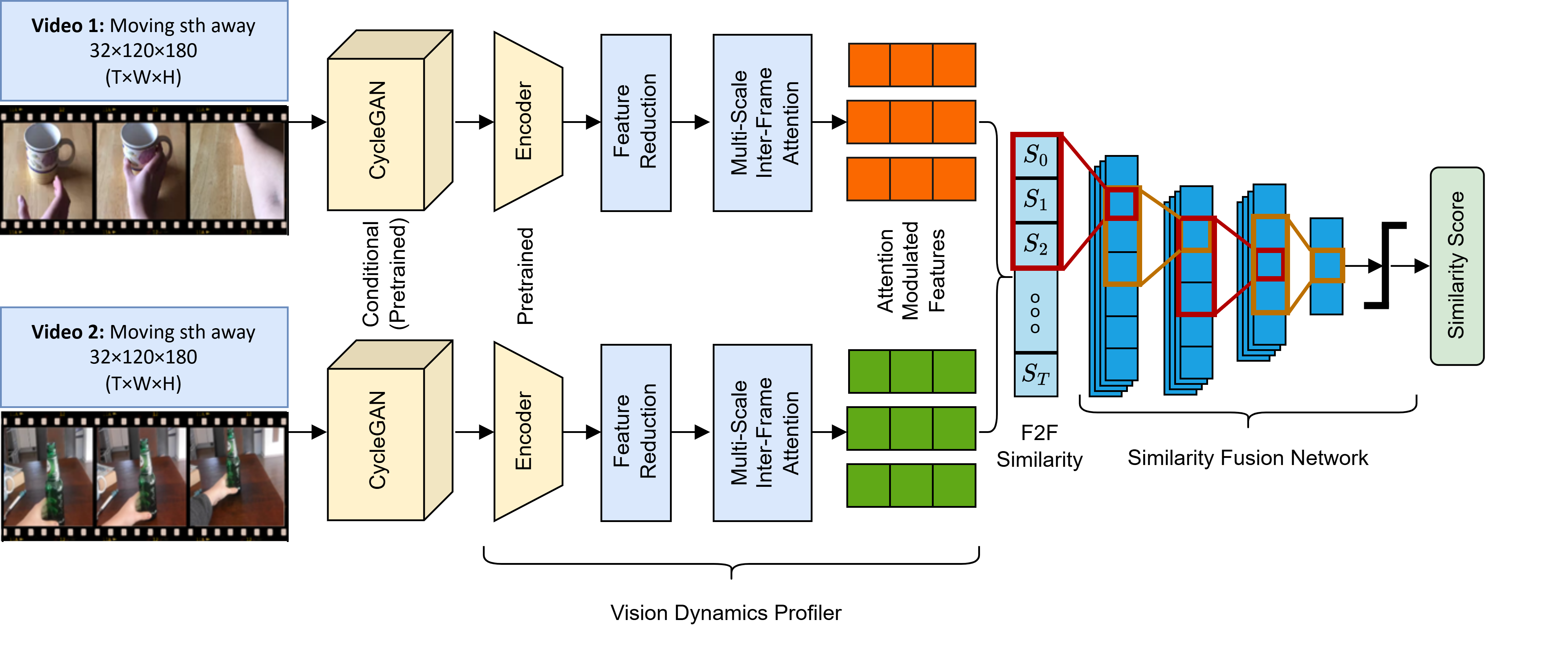
The Vision Dynamics Profiler (VDP) takes conditionally augmented video frames as input to produce frame-level features through a pre-trained encoder. The feature reduction and multi-scale inter-frame attention layers further process these features to output a representation for each video. Frame-to-frame cosine similarity is then calculated between the two videos. The Similarity Fusion Network (SFN) processes the similarity vector through a series of 1D-convolution layers to generate a similarity score.
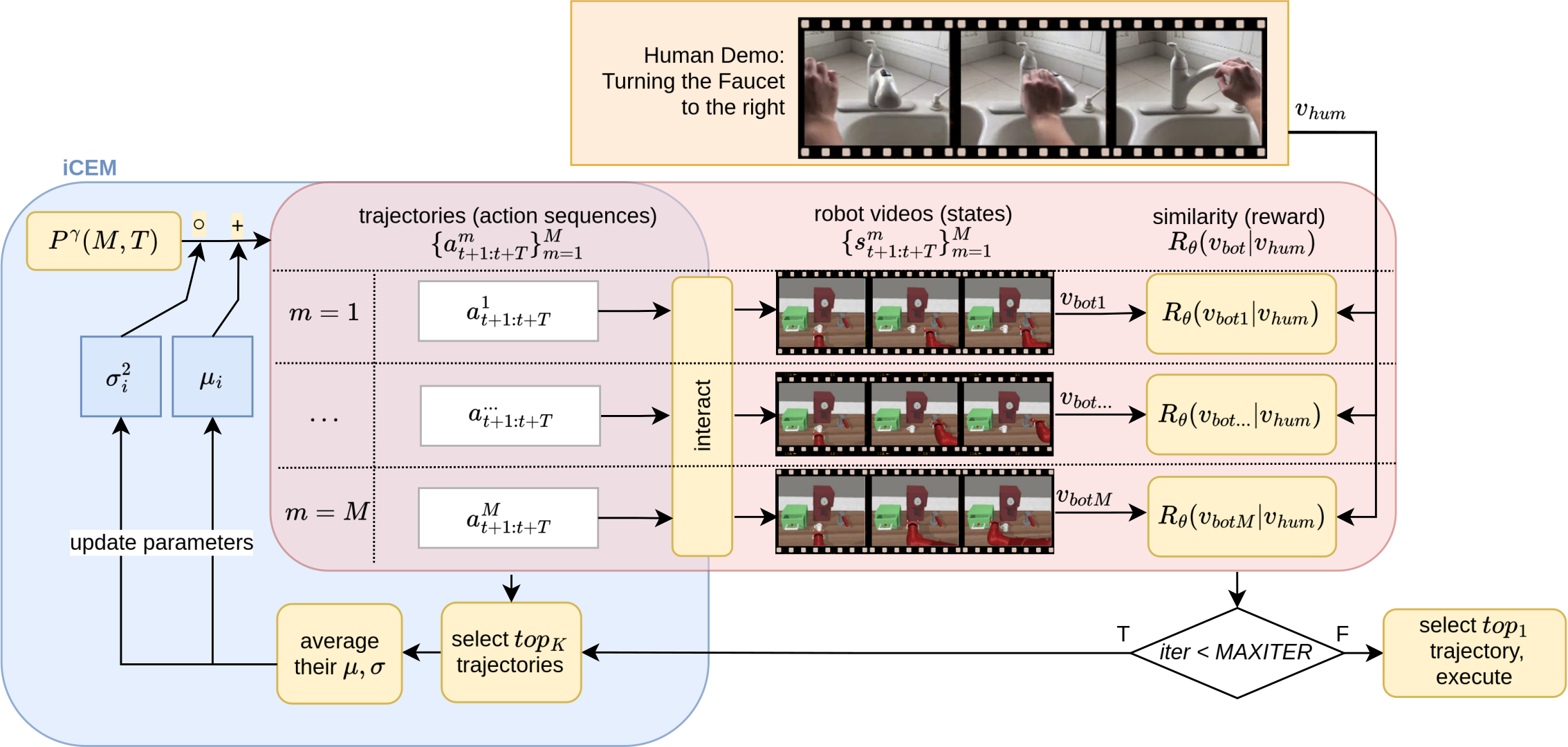
During the final task execution, we used a single human demonstration of the task and sampled robot trajectories from the environment as input. We evaluate all these trajectories using H2B to determine their similarity to the demonstration, and assigning rewards accordingly. iCEM then optimizes its parameters based on the top-K trajectories by rewards to generate trajectories in the next iteration that closely mimic the demonstrated task.
Experimental Setup and Results

Training (left): The agent learns a reward function from numerous human videos encompassing various tasks and environments. Inference (right): Evaluation is conducted across diverse simulated environments and real-robot scenarios, both involving tabletop settings with various interactive objects.


Success rate for three target tasks, showing the impact of increasing non-target training tasks on generalization. The dotted line represents the average success rate.
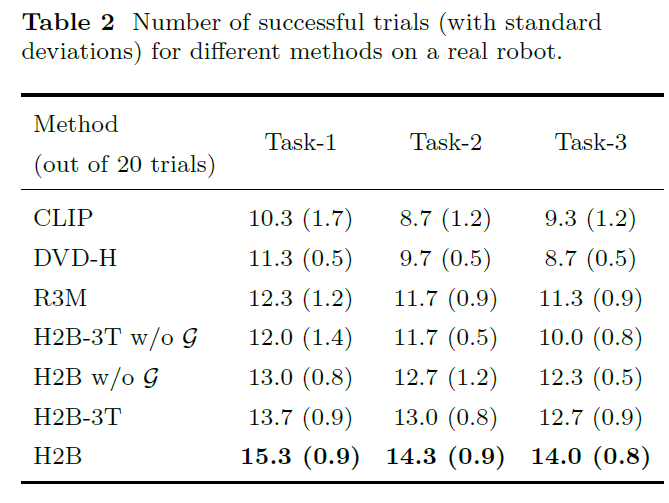
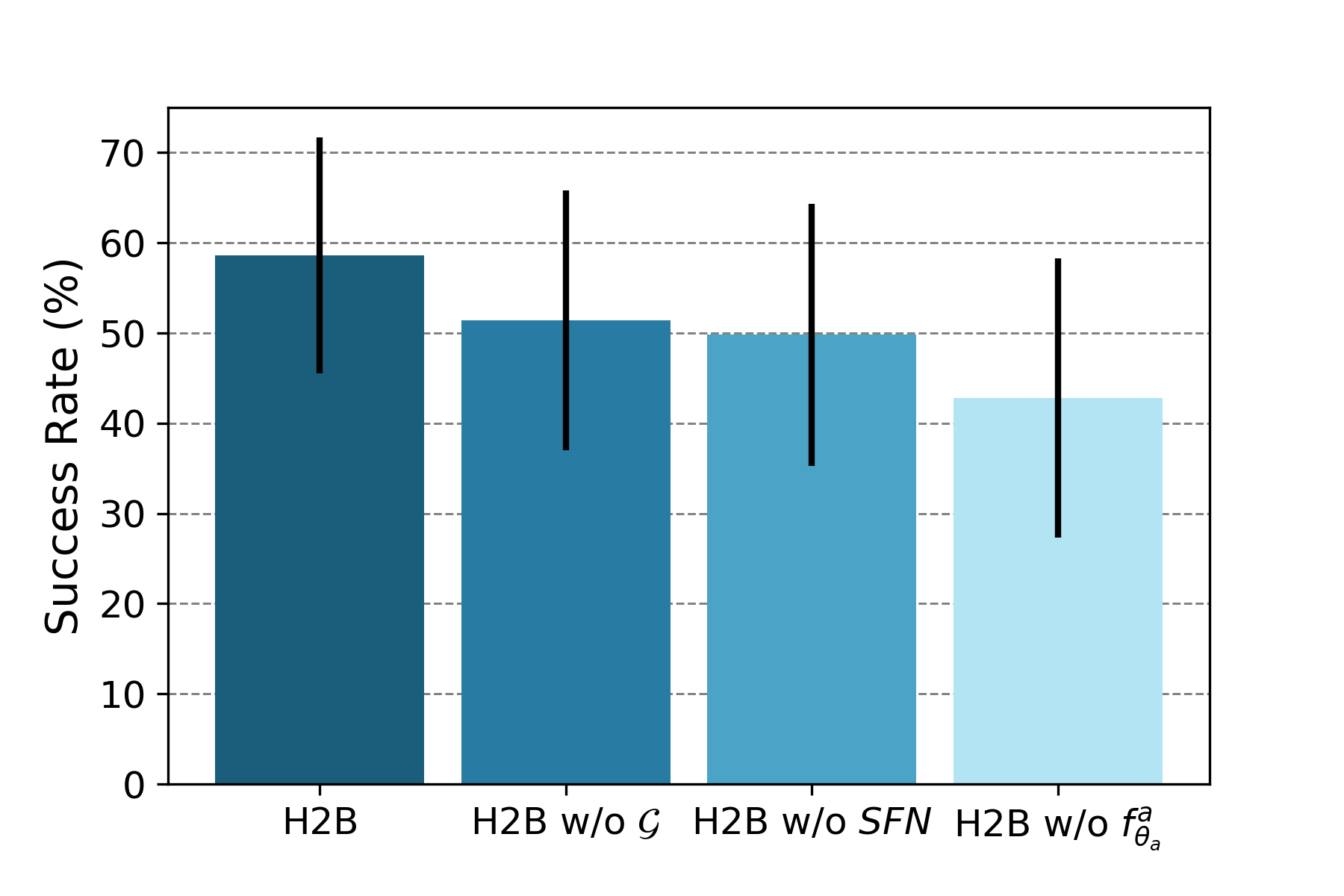
We studied the impact of removing the domain augmentation G, the SFN component SFN, and the multi-scale inter-frame attention mechanism fa on robot task success rates. The error bars indicate the standard deviation.
BibTeX
Will be updated soon.